
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- devtools
- Testing
- ViTE
- CSS
- vue3
- import.meta.env
- n8n
- vue-cli
- 선택자
- JavaScript
- custom command
- CloudFlare
- msw
- QUIC
- caching
- vue
- svelte
- typeScript
- 비동기
- http3
- e2e
- web vital
- TLS
- SSR
- aws
- csr
- api test
- n8n 기초
- Cypress
- ts error
Archives
- Today
- Total
Develop Note by J.S.
[AI] AI를 활용한 서비스 Chatbot 만들기 본문
https://toss.tech/article/tosspayments-mcp
- 위 링크는 토스의 결제 시스템 연동을 MCP 서버를 통해 AI로 쉽게 구현하는 기능 관련 포스트 입니다. MCP서버를 사용하면 결제시스템을 연동하려는 클라이언트가 질문을 하면, 토스 개발자 센터 홈페이지에서 문서들을 토대로 좀 더 디테일한 응답 받을 수 있습니다.
- 제가 참여하고 있는 서비스(대회 운영 스태프의 Back Office Service)의 경우 메뉴얼이 제공되지만 문서량도 많고 일반적으로 사용자가 메뉴얼을 정독하는 사람은 별로 없을 것이고, 궁금한게 있으면 메뉴얼을 보지 않고 직접적으로 물어보기 때문에 1차적으로 Chatbot기능이 있다면 이러한 CS건이 조금 줄어들지 않을까 생각하여 Chatbot 기능을 Try 해보았습니다.
1. MCP(Model Context Protocol)
- MCP(Model Context Protocol)는 AI 모델이 특정 컨텍스트(예: 문서, 데이터)를 기반으로 질문에 답변을 생성하는 프로토콜을 의미합니다. 이를 통해 모델은 사용자 질문에 대해 더 정확하고 관련성 높은 답변을 제공할 수 있습니다.
- LLM이 바로 연결해 사용할 수 있는 다양한 사전 구축된 통합 기능 제공
- LLM 제공업체 간 유연한 전환 가능
- 자체 인프라 내에서 데이터를 안전하게 보호할 수 있는 베스트 프랙티스 제공
2. Flow

- Chatbot에서 질문을 하면 MCP에서 해당 질문이 일반적인(General) 서비스 관련 질문인지, 아니면 진행 중인 특정 토너먼트(Specific Ongoing Tournament)에 대한 질문인지 판단
- General 인 경우 미리 정의한 문서에서 현재 질의어와 매칭하여 Score를 계산 → 4개의 최상위 Score인 Document를 질의어와 함께 AI에 전달
- 특정 토너에 대한 질문인 경우 즉시 return
- Chatbot Client에서는 특정 대회 질문이라고 하면, 특정 JSON 데이터와 함께 /Analyze API를 호출하여 질의어와 함께 다시 전달
- 이후 MCP서버에서 Data DTO의 관련된 Document와 함께 다시 AI로 질문
- 질문에 따라 어떤 API를 매칭하여 데이터를 전달해야 할지 에 대한 문제는 현재 고민 중에 있습니다.
- Code
- MCP Server는 Node Express사용, AI는 Gemini API 사용 (무료라서..)
- 서버 시작 시 llms.txt 에 정의된 문서들을 가져와서 lunr로 document의 index 실행
- llms.txt 내용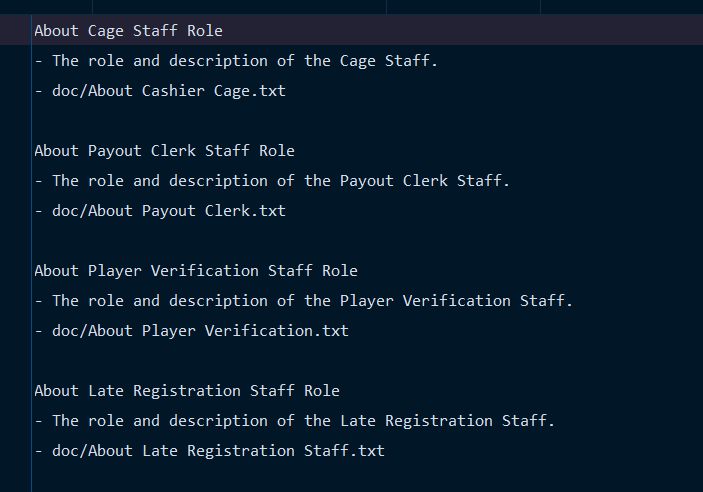
- Doc 파일들// 서버 초기화 (async () => { try { // llms.txt 파일 파싱 및 문서 로드 const parsedDocuments = parseLLMSTxt(LLM_FILE_PATH); documents.push(...parsedDocuments); // 문서 내용 가져오기 및 Lunr 인덱싱 await fetchAndIndexDocuments(documents); console.log('Documents indexed successfully.'); } catch (error: any) { console.error('Error initializing server:', error.message); } })(); // Parse llms.txt file function parseLLMSTxt(filePath: string): Document[] { const raw = fs.readFileSync(filePath, 'utf8'); const lines = raw.split('\n'); const parsedDocuments: Document[] = []; let currentDoc: Partial<Document> = {}; for (const line of lines) { if (!line.trim()) continue; if (!line.startsWith('-')) { // New title if (currentDoc.title && currentDoc.url) { parsedDocuments.push(currentDoc as Document); } currentDoc = { title: line.trim() }; } else if (line.startsWith('- doc')) { // doc로 시작하는 경로를 url로 설정 currentDoc.url = line.replace('- ', '').trim(); } else { currentDoc.description = line.replace('- ', '').trim(); } } // Add the last document if (currentDoc.title && currentDoc.url) { parsedDocuments.push(currentDoc as Document); } return parsedDocuments; } // Fetch content from URLs and index documents async function fetchAndIndexDocuments(documents: Document[]): Promise<void> { for (const [index, doc] of documents.entries()) { try { const filePath = path.resolve(__dirname, '../', doc.url); // Resolve the file path const content = await fs.promises.readFile(filePath, 'utf8'); // Read file content doc.content = content.replace(/\s+/g, ' ').trim(); // Normalize whitespace doc.id = index; // Assign unique ID } catch (error) { console.error( `Failed to fetch content for ${doc.title}:`, error instanceof Error ? error.message : error, ); } } // Create Lunr index lunrIndex = lunr((builder: lunr.Builder) => { builder.ref('id'); builder.field('title', { boost: 10 }); builder.field('description', { boost: 5 }); builder.field('content'); documents.forEach((doc) => builder.add(doc)); }); console.log('Lunr index created successfully.'); }
- Gemini 연동
- Gemini Api model 생성
import { GoogleGenerativeAI } from '@google/generative-ai'; // Gemini API URL const API_KEY = process.env.GEMINI_API_KEY; if (!API_KEY) { console.error( '오류: GEMINI_API_KEY 환경 변수가 설정되지 않았습니다. .env 파일을 확인해 주세요.', ); process.exit(1); } const genAI = new GoogleGenerativeAI(API_KEY); export const model = genAI.getGenerativeModel({ model: 'gemini-2.5-flash' }); // 또는 'gemini-1.5-pro' - 생성한 Prompt를 Gemini에게 질문요청
const classificationResult = await model.generateContent([ { text: classificationPrompt, }, ]);
- Gemini Api model 생성
- 일반적인 질문인지 특정 토너에 대한 질문인지에 대한 prompt

Lunr을 활용한 질문과 Document의 Score계산
- Lunr - Lunr.js는 클라이언트 또는 서버에서 실행 가능한 JavaScript 기반의 검색 라이브러리로, 텍스트 기반 데이터에 대해 빠르고 효율적인 검색을 수행하는 역할을 합니다. 아래는 Lunr.js의 주요 역할입니다:
인덱스 생성: 텍스트 데이터를 기반으로 검색 가능한 인덱스를 생성합니다. 이 인덱스는 검색 속도를 높이고 효율적인 검색을 가능하게 합니다.
- 검색 수행: 사용자가 입력한 검색어를 기반으로 인덱스를 탐색하여 관련 결과를 반환합니다.
- 점수 계산: 검색 결과의 관련성을 점수화하여 가장 관련성이 높은 결과를 상위에 배치합니다.
- 텍스트 매칭: 텍스트 데이터에서 특정 키워드 또는 문구를 매칭하여 결과를 반환합니다.
- 빠른 검색: 대량의 텍스트 데이터에서도 빠른 검색을 수행할 수 있도록 최적화되어 있습니다.
- Lunr - Lunr.js는 클라이언트 또는 서버에서 실행 가능한 JavaScript 기반의 검색 라이브러리로, 텍스트 기반 데이터에 대해 빠르고 효율적인 검색을 수행하는 역할을 합니다. 아래는 Lunr.js의 주요 역할입니다:
- 질문 Prompt
- AI Chatbot으로 써의 답변과 html 형식의 답변을 요구하였고, Document 와 함께 question을 전달


반응형